



A while back, I read a comment on the CivitAI Discord where someone mentioned that training the Text Encoder (TE) shouldn't THEORETICALLY be necessary. Recently, wolf999 published an interesting article (illustrious lora training best settings 2026 sdxl | Civitai) mentioning settings where the TE is left untouched.
However, after several tests, I believe the story is different—at least for Style LoRAs. In this article, I want to explain why I consider training the TE vital for capturing the essence of a style, keeping it simple and free of heavy technical jargon.
What is the TE (Text Encoder)?
In short, the Text Encoder is the translator. It is responsible for converting user text (your prompts) into numbers (vectors) that the UNet can understand. Think of it as the guide giving the UNet coordinates on where to look in its "memory" to draw what you are asking for.
What happens when we train the TE?
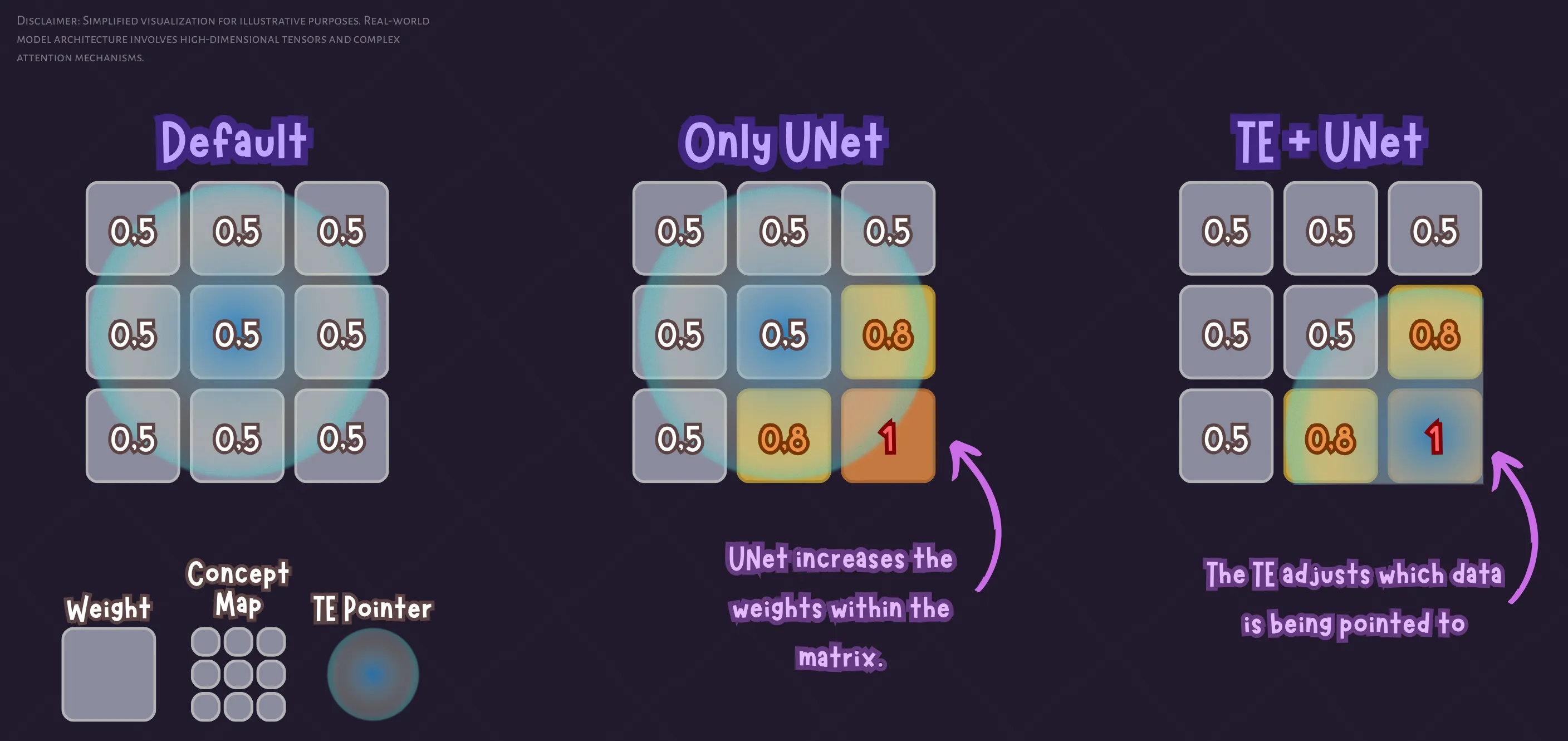
By training the TE, we adjust those "coordinates" to point to a more specific location related to the strokes of the style we are aiming for.
Think of it this way: Illustrious has vast knowledge of how to represent "grey hair."
Without training TE: The model uses its "average" definition of grey hair. The UNet tries to visually force your style, but the underlying concept remains generic. This "dilutes" the style.
Training TE: We tell the model: "When I say 'grey hair', don't look for the average; look for the version of 'grey hair' that matches these artistic strokes."
If we only train the UNet, we reinforce how the image looks, but the TE continues pointing to the generic concept. This creates a constant struggle between the model's base style and your LoRA. By training the TE, we align the concept with the style.

In these example images, I trained 2 LoRas with the exact same settings, except one has the TE training rate at 0.00005 and the other at 0. (Full configuration at the end of the article).
We can see that when training only the UNet, you can indeed tell that something was trained related to the target style. You can see the shadows are harder rather than simply blurred, the anatomy changes slightly, and the color palette shifts. However, you could say the style is effectively being diluted.
Now, when we train the TE, the change is instantly noticeable. We see the facial structure change completely; the shadows that were slightly visible in the UNet-only training are now much more pronounced, along with other style characteristics like the line art.
With this example, we can conclude that training the TE is indeed necessary, at least for Style LoRAs.
I must clarify that this was a 2-day investigation. I skipped over several technical concepts but tried to ensure the information presented here is accurate. If you are knowledgeable about this topic and notice I’ve made a mistake at any point, please let me know! The last thing I want to do is misinform people, and if that happens, I will edit this article as soon as possible to correct the errors.
UPDATE 11/27/2025
It is important to clarify a side effect: by training the TE, we are creating a somewhat "selfish" LoRA. Since we are modifying how the model interprets text, it will likely conflict if we try to mix it with other LoRAs that are also attempting to modify those same rules.
Using the previous infographic, imagine that "pointer" struggling to agree with two different LoRAs simultaneously. This can cause the style to become diluted or, in the worst-case scenario, introduce visual artifacts.
User n_Arno brought up an interesting point in the comments: if the dataset is perfectly tagged, training the TE shouldn't be necessary, as the UNet would learn to associate those tags with the visual style.
While this is a valid approach for certain cases, I see two main issues when it comes to Style LoRAs:
Manual Tagging: Tagging absolutely everything visible in every single image is a massive undertaking.
Generalization: This is the key point. If a chair never appears in your style dataset, a UNet-only training will likely draw a generic chair that doesn't fit with the rest of the image. By training the TE, the model learns to "interpret" any concept through the lens of your artistic style. (Note: This is purely theoretical; I haven't run specific tests to back this claim up yet).
If you notice artifacts when combining your Style LoRA (with TE) with other resources, there are simple solutions I’ve successfully tested:
Lowering the Strength: I ran some tests combining exactly 5 LoRAs. At full weight (1.0), you could practically see the model screaming in agony trying to produce a result. However, when using multiple LoRAs, we usually say: "Hmm... give me a bit of this, a bit more of that... or I definitely want that specific anatomy so...", which results in varied weights (e.g., 0.2, 0.3, 0.8, 0.6, 0.6). Even with this approach, I encountered artifacts in specific cases (like the headphones in this example). The fix? I simply lowered that specific LoRA's weight from 0.8 to 0.7. While this largely solved the issue, it feels like more of a superficial fix.
Choosing the Right Epoch: The solution that worked best was selecting an earlier epoch. I generally train my LoRAs for 10 epochs, but I always test both epoch 10 and epoch 8. If epoch 8 looks virtually identical to epoch 10, I always choose the 8th one. Even if epoch 10 doesn't show signs of overfitting, I prefer sticking with epoch 8 to leave myself much more "headroom" for combining weights later on.
LoRa Configuration
Base Model: Illustrious V1.0
Repeats: 5
Epoch: 10
Steps: 990
Batch Size: 4
Clip Skip: 1
UNet learning rate: 0.0005
LR Scheduler: cosine_with_restarts
lr_scheduler_num_cycles: 3
Optimizer: AdamW8bit
Network Dim: 32
Network Alpha: 16
Min SNR Gamma: 5
Noise Offset: 0.1
Multires noise discount: 0.3
Multires noise iterations: 8
Zero Terminal SNR: True
Shuffle caption: TrueThat’s it!
Stay hydrated and don’t forget to blink.
